Drone Newspaper Article Sentiment Analysis
Class project for Drones and Society (University of Utah Honors 3374-002)
A Look at Media Coverage of Domestic and Foreign Drone Use in the US
Nicolas Goller, Dominic Austin, and Tyler Shimko
Introduction
As the military and civilian uses of unmanned aerial systems, known colloquially as "drones," have increased in recent years, so has the media coverage of the subject. However, unbiased analysis of this coverage has been minimal at best. Many of the military uses of drones are associated with negative outcomes, including death and unnecessary collateral damage, in the eyes of general public. In contrast, the domestic uses of drones, including delivery service and environmental monitoring, tend to have more positive connotations. In this study, we objectively examine the media sentiment toward the domestic and foreign uses of drones. We seek to determine an automated and quantitative method for the word-by-word analysis of this media coverage.
Methods
Of primary concern for this study was the accurate and complete collection of the relevant data for analysis. We utilized the news media archiving tool LexisNexis to collect all of the articles referencing "drones" that were published in the past year. In order to build up our analysis, we selected three papers with significant circulation that represented reasonable geographic spread. We were limited by the availability of archives on LexisNexis. We eventually ended up selecting the New York Times, Washington Post, and Denver Post due to a combination of geographic spread, circulation, and archive availability.
Article Collection and Formatting
We pulled all of our data down from LexisNexis using the keyword "drones" for The New York Times, The Denver Post, and The Washington Post. LexisNexis had all of the articles for these newspapers and they are fairly well known. Additionally, several thousand articles seemed like a reasonable dataset. The specific newspapers were chosen based on The date range of one year landed articles between October 31, 2013 and October 30, 2014 inclusively. Since this query yielded 2,954 articles and LexisNexis only allows the download of five hundred articles at a time, we were forced to download the articles in six segments. We then split those six files of articles into 2,954 different files such that each file contained one article. (xxxx01.txt, xxxx02.txt, etc).
Using these files, we parsed out the relevant data from each file - the article's newspaper name, date, length, title, and body - and placed these data on a row separated by caret characters as the caret did not appear in any of the articles. LexisNexis outputs the articles in regular pattern so parsing the articles is not too difficult. We wrote a short Java program to parse the files in the following manner:
Look for a line containing the newspaper title and then stop looking for it once found (searching for keywords "york", "washington", and "denver" proved to be sufficient). All articles had one of these three keywords in the proper location at the beginning. LexisNexis sets up the file this way.
The next couple of lines hold the article date. Look for a line containing the years in the range (2013 - 2014 in our case). We then trim this line and take only the first three tokens of the date (separated by spaces). This gets rid of the specific time, time-zone, and day of the week that was sometimes included.
The title comes next so we keep adding the strings of each line until we run into a line starting with the keyword "BYLINE", "SECTION", or "LENGTH". Sometimes no section or byline was listed, but we are guaranteed to at least find a length and then we know that we have captured the whole title.
Once we find the LENGTH keyword, we record the value following that keyword on the line.
We begin creating a string of the articles once we pass the "LENGTH" keyword as this marks the beginning of the main body. We stop adding lines to the article body once we run into one of the following keywords: "LOAD-DATE", "LANGUAGE", or "PUBLICATION-TYPE". Publication type was always specified while the other two sometimes showed up no the line above and thus needed to be excluded from the body data.
So we basically stepped through each file and pulled out the newspaper the article came from, the date the article was written, the title, the body, and the length of the article. We then put this data into another file where each article corresponded to a row and the five strings of data were separated by a caret character. With these steps, the file was ready for processing.
Duplicate Removal
Duplicate articles were removed from the dataset through an analysis of the correlation of fractional word composition. For each individual article, the number of occurrences was counted. These values were then normalized by article length to yield the fraction of the article composed of each individual word. A correlation value was calculated between each article pair's vectors of composition values and the second article was removed if the value exceeded 0.99. This process removed 832 of 2,954 articles.
Sentiment Calculation
Each article was looped through with each word being compared to the AFINN sentiment dictionary. Each word in the article was therefore assigned a sentiment value. This process yielded a vector of values for each word in the article which were subsequently summed to yield the final sentiment value for the article.
Article Categorization (Manual)
Based on our hypothesis, we needed to divide our sample into our three categories. Foreign articles involved drone strikes, military involvement with drones, foreign possession of military drones, and foreign policy involving drones. Usually these articles talked about terrorism or the countries Afghanistan, Iran, Somalia, or Pakistan. Another common trend of these articles discussed Obama and his foreign policies. The domestic category consisted of articles that involved recreational drones and any policies only affecting the corresponding nation. This could also include public drone crashes or public concern over invasion of privacy. Domestic refers to any local drones within any country that was military related. The junk category contained articles that either didn't involve drones or briefly mentioned drones but was too brief to provide any significant analysis. Sometimes the article would mention drones briefly but move one to the rest of the story. Some articles used the word "drone" pertaining to sound so many articles involved music and bands.
Using one hundred articles to build a sample categorization to train our program to analyze the much larger sample, we predicted that the foreign category would have the greatest number of samples because we believe that drone strikes attract more public attention than any domestic or recreational drone use. Our assumption was correct and the foreign category was the largest. However the number of domestic articles was significantly less than the number of foreign articles which was expected but not to this degree. The category was actually the smallest of the three and was easily outnumbered by junk and foreign. The size of the junk category was larger than we expected, involving anything from article about bands to aging cheese in New York. Unfortunately this article revealed how much of our sample was irrelevant to our purpose, however it's important we remove them for accuracy. These categories will be used as a template algorithm for our program to categorize the rest of sample, so that we don't have to analyze each article independently.
Article Categorization (Automated)
A training set of article categorizations was first formed. This training set categorized 100 articles into the following categories: domestic uses, foreign uses, or junk. We then utilized k-nearest neighbors classification to classify the remaining articles into the categories "junk" and "not junk." In this step we chose to categorize based on the two nearest articles. Using cross-validation, we estimate this step to be roughly 79% accurate. Following this step, the articles categorized as "junk" (721 articles) were removed from the corpus and the remaining articles were categorized into "domestic uses" and "foreign uses." In this step we utilized the five nearest article to classify upon. This classification step yielded an estimated accuracy of roughly 75%. Overall accuracy for our classification algorithm is therefore estimated to be roughly 60%.
Results/Discussion
The two populations of articles differed significantly in their overall sentiments. The population of articles categorized as "domestic" had a mean sentiment value of 5.69 while the articles categorized as "foreign" had a mean sentiment value of -7.98. Overall, the articles categorized as "foreign" were far more negative than ones categorized as "domestic" (p=0.000307). This is most likely the result of the topics covered in the articles on the foreign uses of drones covering more gruesome issues than the domestic articles. Additionally, this trend did not appear to be dependent on the newspaper covering the stories, as domestic stories were consistently more positive in each of the three newspapers examined. The articles covering foreign topics had a larger variance, however, than the domestic articles. while the domestic articles all hovered around the mean sentiment value, there were many examples of foreign uses that were far more positive than even the most positive domestic articles. This was counterbalanced by the fact that there were also many largely negative articles covering the foreign uses of drones.
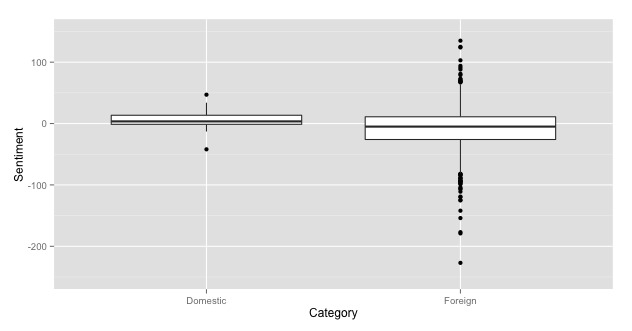
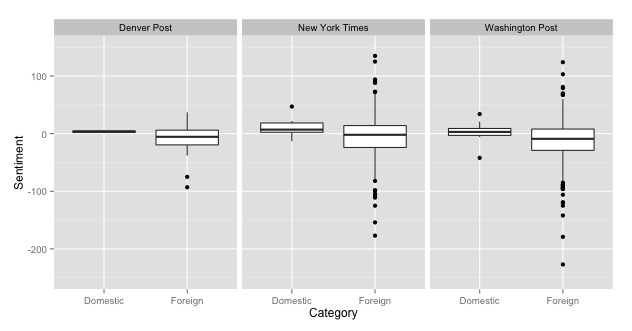
Our analysis convincingly demonstrates that media coverage of the foreign uses of drones are portrayed in a more negative fashion in the media than the domestic uses. However, our analysis does have some limitations. Primarily, we only analyzed three newspaper, all from major metropolitan areas and without a specific focus on a singular subject matter, for example defense or technology. Our findings may very well have been different if we had selected a different form of media (i.e. blogs or web-based news sources) because of the freedom to explore more radical ideas using the internet as a platform. Additionally, we only examined one year's worth of articles. Major foreign drone strikes in the past year may have skewed the negative connotation of these actions even further negative then would be normal over a 5 or 10 year span. This analysis sets the stage for future large scale analysis of media sentiment toward drones.
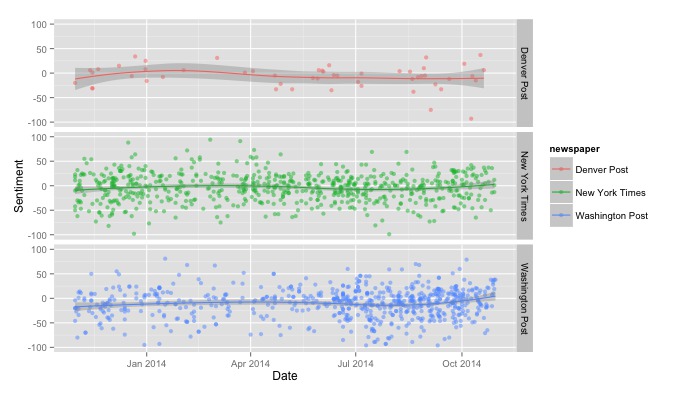
We found that the average sentiment was negative. This can be seen across all three news sources. The Denver Post published relatively few articles about drones. This is likely due to the fact that it is a smaller news organization. The number of articles being written picked up quite significantly around July for The Washington Post and not so dramatically for the other two. The best fit lines are fairly straight, though there is a small increase in sentiment over time.
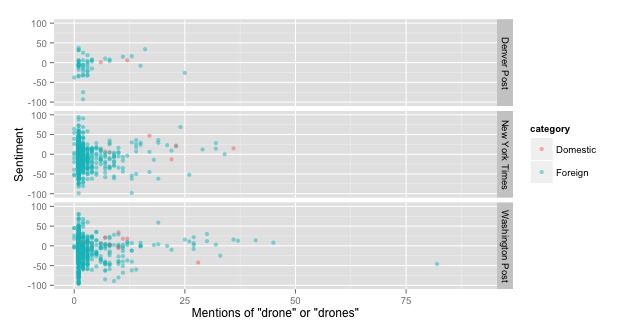
We counted the number of occurrences of the word "drone" or "drones" in the articles. It turns out that the majority of the articles had between one and ten references. This suggests that the average length of the articles was pretty short. According to our results, in the past year, articles had were more foreign-minded than domestic. This is illustrated by the relative lack of red dots in the figure below. It is a bit surprising that we have so few domestic articles as there is a lot of discussion happening as the FAA seeks to provide some form of regulation for drones in the national airspace. It is quite possible that we will see many more domestic articles in the years to come. Unfortunately, in this study we did not have a great deal of this data. There does appear to be a general trend that sentiment goes up as frequency of the words "drone" and "drones" increases. It seems the positivity of the article increases as length increases. It is somewhat unclear as to what this suggests. One to five occurrence articles seem to be pretty negative.
The number of articles published per week clearly increased over time. This makes a lot of sense. As drones become more and more prevalent, we are seeing more and more articles about them. There is also the possibility that The Washington Post simply writes many more articles during the summer. More investigation would be required to confirm the suspicion that drone articles are becoming more widespread.
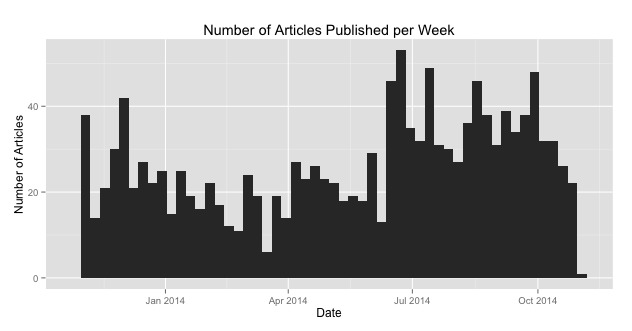
We can conclude that more articles were published by The New York Times, The Washington Post, and The Denver Post later in 2014 than earlier. We also have pretty clear results demonstrating that domestic articles are more positive than the foreign articles.